BERTScoreとは
テキスト生成に対する自動評価指標のこと
BERTScore計算方法
準備
入力として正解文字列を$$x=<x_1, x_2, …, x_k > $$ 出力文字列を$$ \hat{x}=<\hat{x_1}, \hat{x_2},…,\hat{x_m}> $$ と置く。
BERTSCORE
$$ R_{BERT}=\frac{1}{|x|} \Sigma_{x_i \in x}max_{\hat{x}_j \in \hat{x}} \mathbf x_i^T \mathbf{\hat{x}}_j $$
$$ P_{BERT}=\frac{1}{|\hat{x}|}\Sigma_{\hat x_j \in \hat x} max_{x_i \in x} \mathbf x_i^T \mathbf{\hat{x}}_j $$
$$ F_{BERT}=2\frac{P_{BERT}\cdot R_{BERT}}{P_{BERT}+R_{BERT}} $$
計算例
例えば正解文字列(TARGET)が"alphabet"で、生成文字列(OUTPUT)が”writing system”である場合を考える。
数式で表すと 正解文字列を$x=<x_1>=<alphabet> $ 出力文字列を$ \hat{x}=<\hat{x_1}, \hat{x_2}>=<writing, system> $と表せる
Recallの計算例
このときまず
$$ R_{BERT}= \frac{1}{|x|} \Sigma_{x_i \in x}max_{\hat{x}_j \in \hat x} \mathbf x_i^T \mathbf{\hat{x}}_j $$
$$ =\frac{1}{1} \Sigma_{x_i \in {alphabet}}max_{\hat{x}_j \in {writing, system}} \mathbf x_i^T \mathbf{\hat{x}}_j $$
の計算結果がRecallの結果となる
文字での説明では、alphabetとwritingの内積、alphabetとsystemの内積を取って値が高い方がRecallの計算結果となる
図で説明すると、
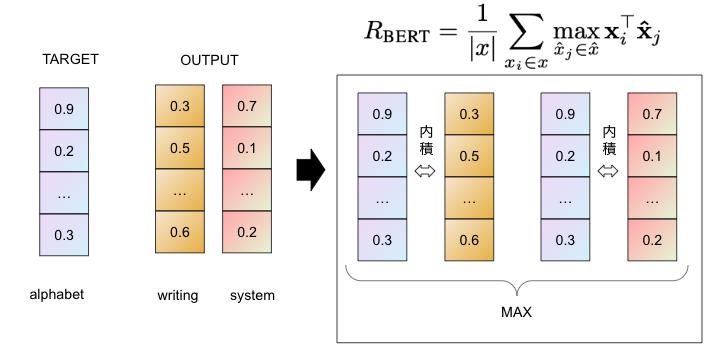
TARGETの「alphabet」とOUTPUTの「writing」の内積を計算し、TARGETの「alphabet」とOUTPUTの「system」の内積を計算し、最大となる内積の結果をRecallの値となる
Precisionの計算例
$$ P_{BERT}=\frac{1}{| \hat x |} \Sigma_{\hat x_j \in \hat x} max_{x_i \in x} \mathbf x_i^T \mathbf{\hat{x}}_j $$
$$ =\frac{1}{| 2 |}\Sigma_{\hat x_j \in \lbrace writing, system \rbrace} \mathbf x_i^T \mathbf{\hat{x}}_j $$
の計算結果がPrecisionの結果となる
図で説明すると
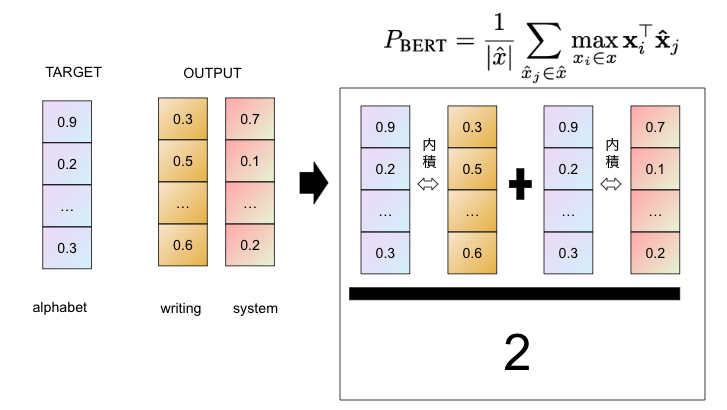
TARGETの「alphabet」とOUTPUTの「writing」の内積を計算した結果と、TARGETの「alphabet」とOUTPUTの「system」の内積を計算した結果を加算し、最終的にOUTPUTの長さ2を割った結果がPrecisionの結果となる。
既存評価指標の問題点
テキスト生成の評価には、これまでBLEUスコアやMETEORスコアを用いられてきた。 しかし、文字列の表面的な適合度のみを評価していた。
例
例えば、正解分としてpeople like foreign cars
という分が与えられるとする。
このとき、BLEUとMETEORスコアではpeople like visiting places abroadに高評価を与える一方で、consumers prefer imported carsの文にはスコアは低い
このように、文の意味を考慮せずに表面的な適合度のみで評価を行う点がBLEUやMETEORスコアの良くない点である。
そこで、文の意味を考慮した評価を行うために導入されたのがBERTScoreである。
参考文献
Zhang, Tianyi, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. “Bertscore: Evaluating text generation with bert.” arXiv preprint arXiv:1904.09675 (2019).