Ke, Pei, Haozhe Ji, Yu Ran, Xin Cui, Liwei Wang, Linfeng Song, Xiaoyan Zhu, and Minlie Huang. “JointGT: Graph-Text Joint Representation Learning for Text Generation from Knowledge Graphs.” In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp. 2526-2538. 2021.
要約
知識グラフからテキストを生成する言語モデルを開発を行った論文
既存のBart、T5といった言語モデルでは、KG-to-textのタスクでグラフ構造を無視して質問を生成していた。そこで、この論文では、グラフ-テキストを同時に学習するモデル(JointGT)モデルを提案
アルゴリズム
・タスク定義とモデルの全体像
知識グラフ$\mathcal{G}=(\mathcal{V,E})$が与えられる。
$\mathcal{V}={e_1, e_2,…, e_{|\mathcal{V}|}}$ は、エンティティーの集合を表していて
$\mathcal{E}=(r_{ij})_{|\mathcal{V}| \times |\mathcal{V}|}$ は、エンティティ間をつなぐリレーションを表す。
そして、これらのグラフを線形化したものを $\mathcal{G}_{linear}=(w_1, w_2,…,w_m)$ と表し、m個のトークンからなる文字列を表す
最終的な目標として、$X=(x_1, x_2, …, x_n)$ 入力のグラフに対応する出力$X$を求めることである。
・・線形化手法
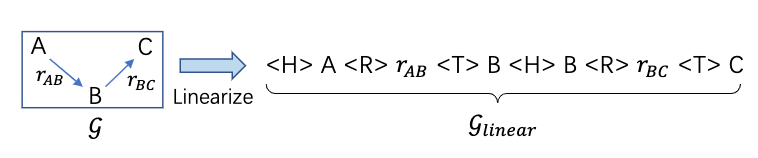
・モデル構造
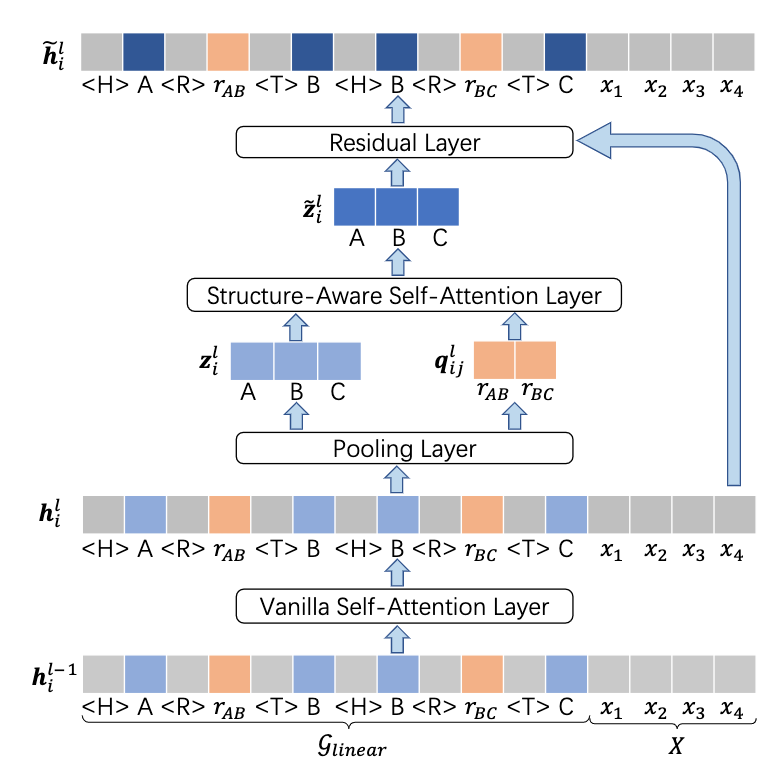
隠れ層の計算には一般的な自己注意機構に加えて、構造に着目した層を加えて隠れ層を求める。
・・一般的な自己注意機構の層
$$\boldsymbol{h_i}^l=\Sigma_{j=1}^{m+n}\alpha_{ij}^l(\boldsymbol{h_j}^{l-1}\boldsymbol{W}^V)$$ $$\alpha_{ij}^l=\frac{exp(t_{ij}^l)}{\Sigma_{p=1}^{m+n}exp(t_{ip}^l)}$$
$$t_{ij}^l=\frac{(\boldsymbol{h}_i^{l-1}\boldsymbol{W}^Q)(\boldsymbol{h}_j^{l-1}\boldsymbol{W}^K)}{\sqrt{d_k}}$$
$$i=1,2,…,m+n$$
$$\boldsymbol{W}^Q, \boldsymbol{W}^K, \boldsymbol{W}^V$$はそれぞれquery, key valueベクトルを表す
しかし、一般的な自己注意機構だけでは、入力グラフのグラフ構造の情報が失われてしまう。
そこで、本研究では、構造に着目した層も新たに加えた
・・pooling層
$$ \mathbf q_{ij}^{l}= \text{pooling} \left( \mathbf h_p^l | p \in \mathcal(P)\left( \text{r}_{ij} \right) , 1 \leq p \leq m \right) $$
で、エンティティの隠れ層の情報とリレーションの隠れ層の情報を取得する
$$ \mathcal{P}(e_{ij})/\mathcal{P}(r_{ij}) $$
は、線形化されたグラフでエンティティの集合とリレーションの集合をそれぞれ表す。
・・(strucutre-aware self-attention layer)構造に着目した自己注意層
$$ \tilde{\mathbf z_i^l}=\sum_{j=1}^{\lvert \mathcal V \rvert} \beta_{i j}^l\left(\mathbf z_{j}^{l} \mathbf W^{VS}+\mathbf q^{l}_{ij} \mathbf W^{VR}\right) $$
$$ \beta_{i j}^{l}=\frac{\exp \left(u_{i j}^{l}\right)}{\sum_{p=1}^{|\mathcal{V}|} \exp \left(u_{i p}^{l}\right)} $$
$$ u_{ij}^{l}=\frac{\left(\mathbf z_{i}^{l} \mathbf W^{QS}\right)\left(\mathbf z_{j}^{l} \mathbf W^{KS}+\mathbf q_{ij}^{l} \mathbf W^{KR}\right)^{\top}}{\sqrt{d_{k}}} $$
$$i=1,2, \cdots,|\mathcal{V}|$$
・・Residual Layer(残差層)
$$ \tilde{\mathbf h_{i}^{l}}=\begin{cases}\mathbf h_{i}^{l}+\tilde{\mathbf z_{j}^{l}}, & i \in \mathcal{P}(e_{j}) \ \mathbf h_{i}^{l} & \text { otherwise. }\end{cases} $$
$$ i=1, \cdots, m+n ; \quad j=1, \cdots,|\mathcal{V}| $$
・ 学習手法
Graph Enhanced Text ReconstructionとText Enhanced Graph ReconstructionとGraph-Text Embedding Alingnmentの3つのアルゴリズムを用いて事前学習を行う
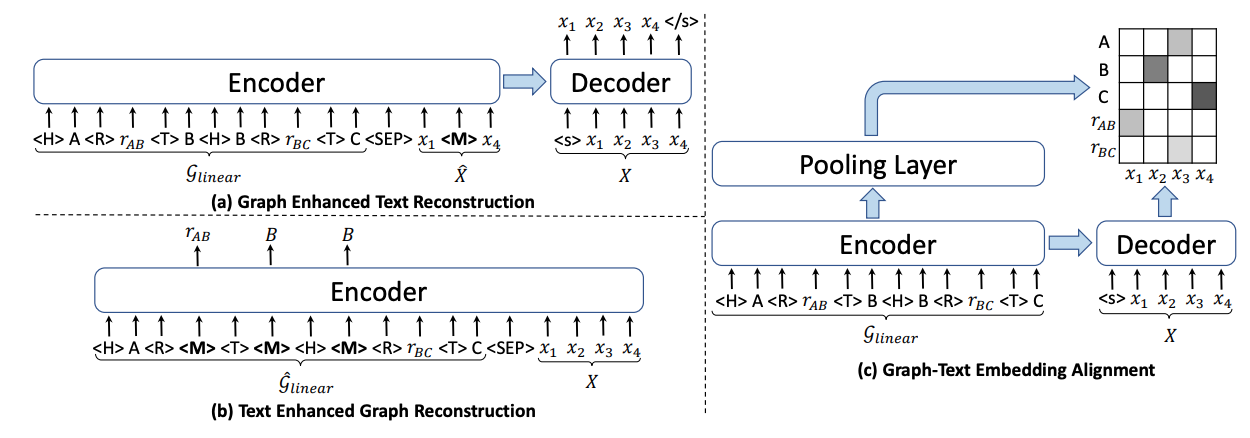
・・Graph Enhanced Text Reconstruction
$$ \begin{aligned} \mathcal L_{t e x t} &=-\log P(X \mid \mathcal{G}, \hat{X}) \ &=-\sum_{i=1}^{n} \log P\left(x_{i} \mid \mathcal{G}, \hat{X}, x_{<i}\right) \end{aligned} $$
・・Text Enhanced Graph Reconstruction
$$ \begin{aligned} \mathcal L_{g r a p h} &=-\log P(\mathcal G \mid \hat{\mathcal G}, X) \ &=-\sum_{i=1}^{m} M_{i} \log P\left(w_{i} \mid \hat{\mathcal G}, X\right) \end{aligned} $$
・・Graph-Text Embedding Alingnment
$$ \mathcal L_{O T} =\min_{\mathbf T \in \Pi(\mathbf a, \mathbf b)} \sum_{i=1} \sum_{j=1}^{n} \mathbf T_{i j} \cdot d\left(g_{i}, x_{j}\right) \ \Pi(\mathbf a, \mathbf b) $$
$$ =\lbrace \mathbf T \in \mathbb R_{+}^{(\lvert \mathcal V \lvert+ \rvert \mathcal E \rvert) \times n} \mid \mathbf T \cdot \mathbf 1_{n}=\mathbf a, T^{\top} \cdot \mathbf 1_{|\mathcal V|+|\mathcal E|}=\mathbf b \rbrace $$
データセット
事前学習では、KGTEXTと呼ばれるデータセットを使用
評価結果
