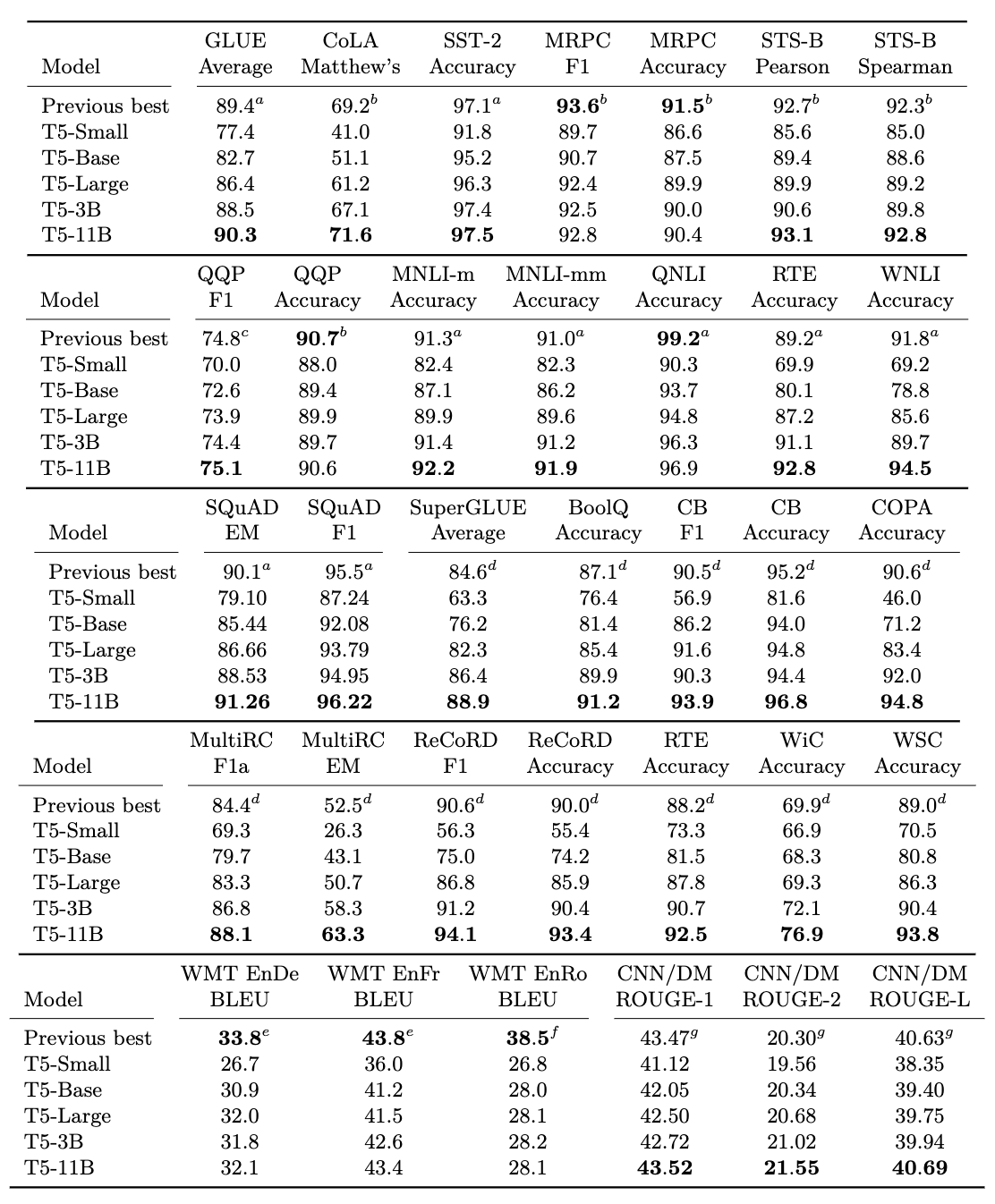
T5結果
Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. “Exploring the limits of transfer learning with a unified text-to-text transformer.” J. Mach. Learn. Res. 21, no. 140 (2020): 1-67.
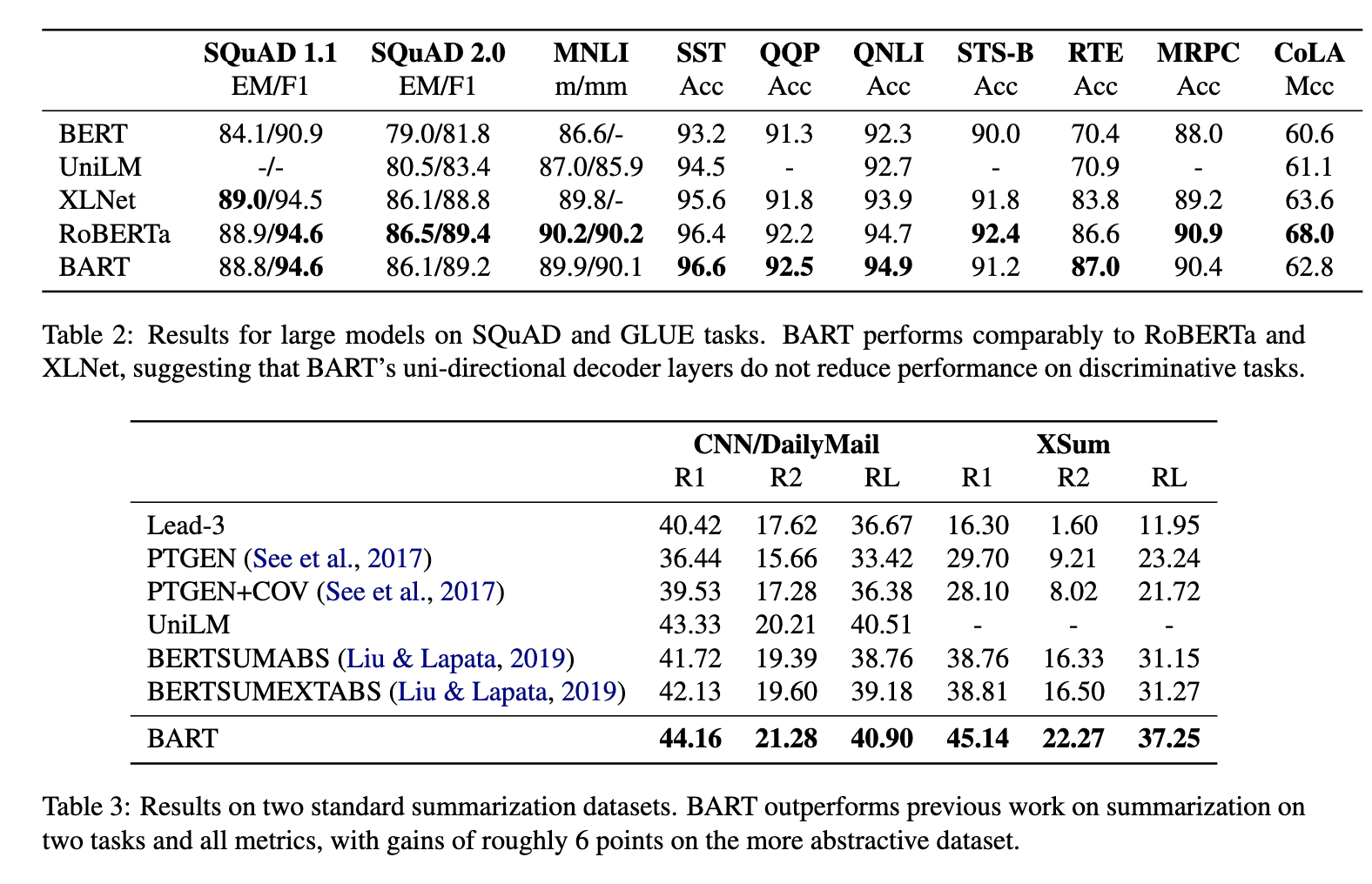
BART結果
Lewis, Mike, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.” arXiv preprint arXiv:1910.13461 (2019).
比較
SQuADではBARTモデルのほうが良い結果
しかし、MNLI,SSTといったタスクではT5モデルのほうが良い結果
→タスクによってT5が良かったり、BARTが良かったりする