日本語固有表現抽出を以下にまとめる
BIDDING DATASET
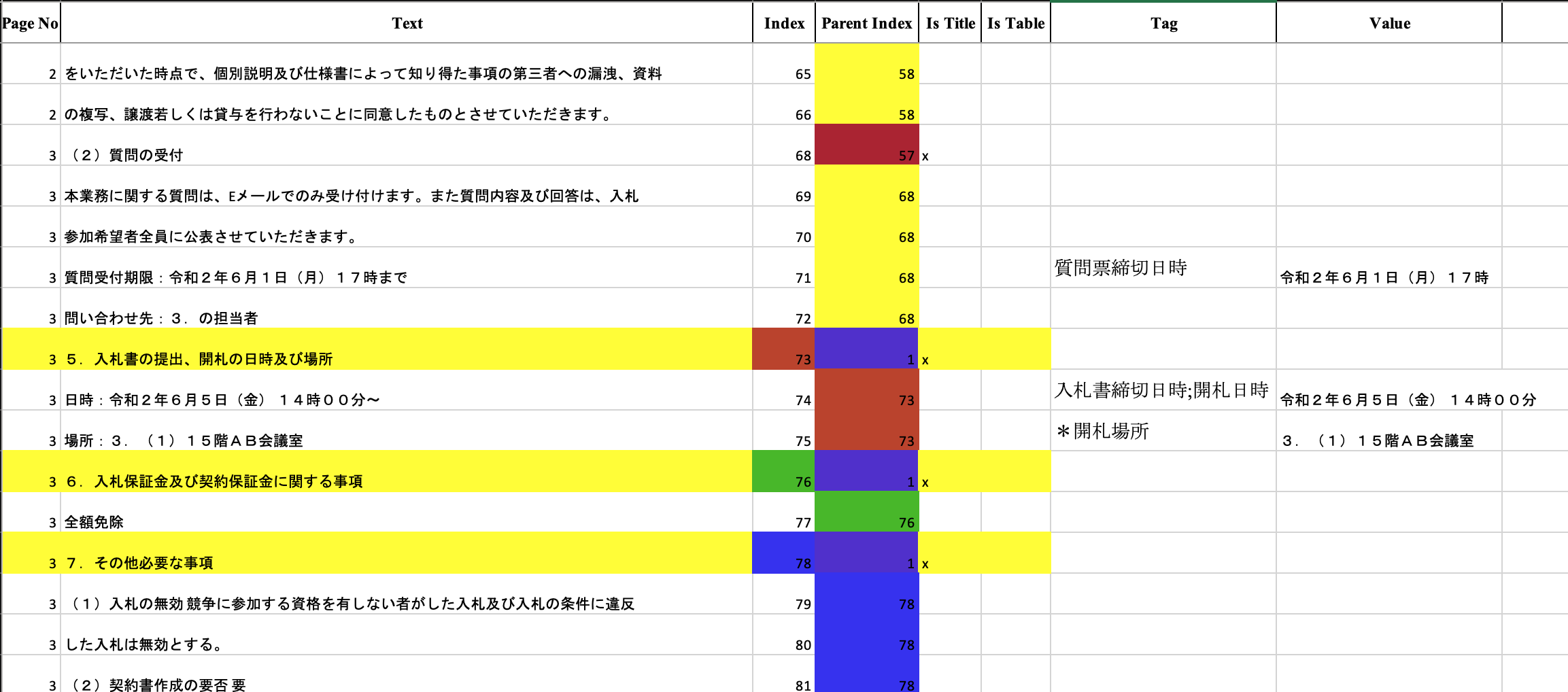
入札に関するPDFと「調達年度、都道府県、入札件名、施設名、需要場所(住所)、調達開始日、調達終了日、公告日、仕様書交付期限、質問締切日時、資格申請締切日時、入札書締切日時、改札日時、質問箇所 所属/担当者、質問箇所 TEL/FAX、資格申請送付先、資格申請送付先 部署/担当者名、入札書送付先、入札書送付先 部署/担当者名、改札場所」の固有表現を抽出するデータセット
PDFは以下のようになっている




正解ラベルはExcel形式
データスタッツ
Wikipediaを用いた日本語の固有表現抽出データセット
Wikipediaのテキストに対して、タグ(タイプ)を「人名、法人名、政治的組織名、その他の組織名、地名、施設名、製品名、イベント名」を割り当てたデータセットリンク
固有表現をハイライトしたサンプルは以下の通りリンク

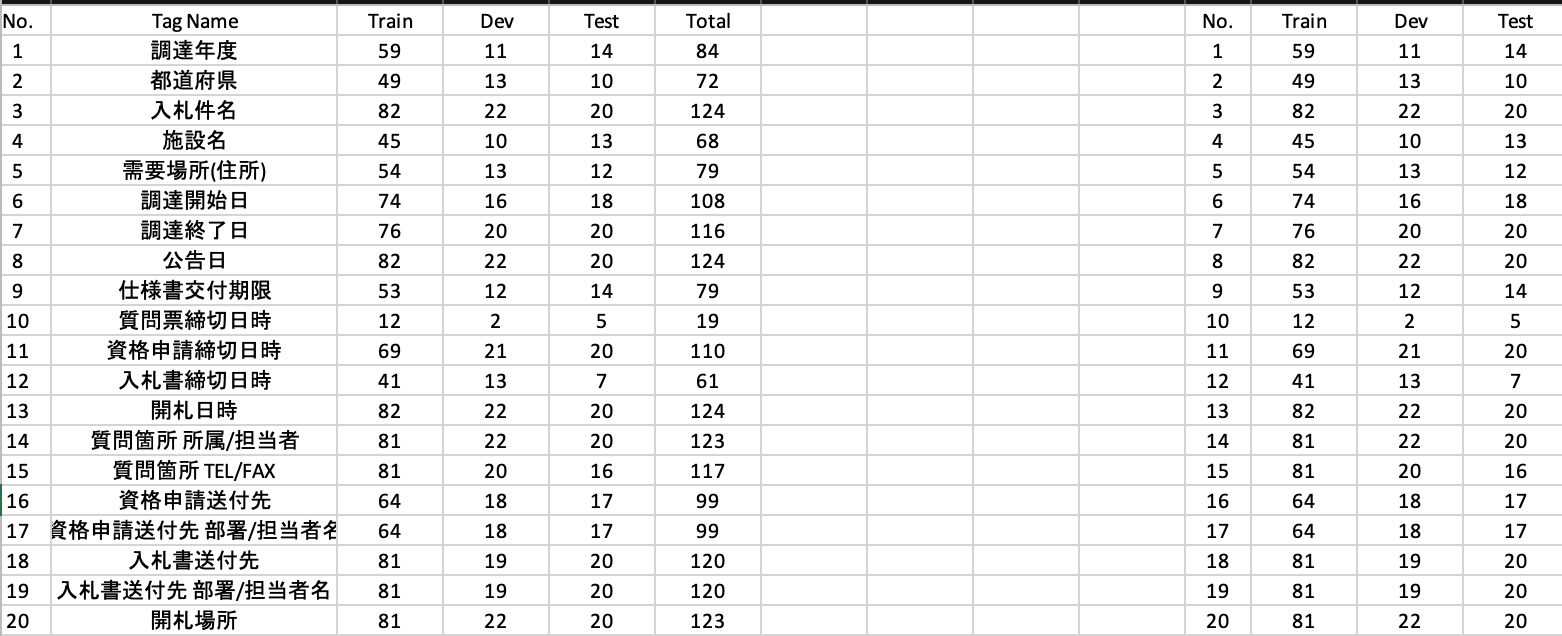
データ形式 データファイルはjson形式になっており、全体としてはデータサンプルのリストとして構成されている
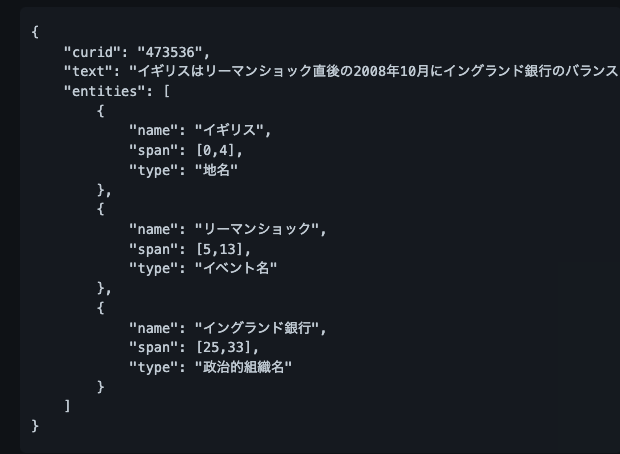
- curidは、データ元のWikipediaのページID
- textはタグ付けを行う対象のテキスト
- entitiesは固有表現のリスト
- nameは固有表現名
- spanはtextでの位置
- typeは固有表現のタイプ
IREXコーパス
毎日新聞の94,95年の記事を対象にした固有表現抽出データセット
新聞記事データは含まれていない点に注意が必要
データセットのダウンロードはこちら
日本語HPはこちら
このHPに詳しく各フォルダの中身について解説がされている
京都大学ウェブ文書リードコーパス
さまざまな種類のテキストに対する固有表現抽出を行なったデータセット
具体的にはWebやニュース、百科事典、ブログ、広告といった幅広いジャンルのテキストから固有表現を抽出したデータセット
データの形式は以下の通り
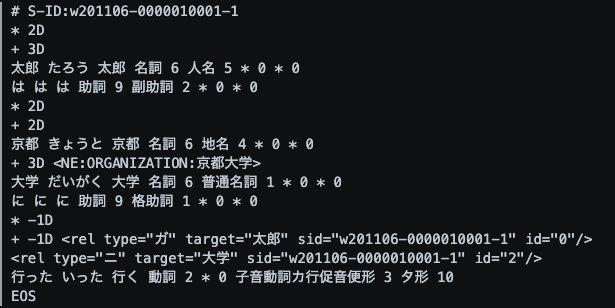
- 最初の行は文章のIDを表す
- *は文節を表す
- 文節は1つもしくは複数の単語で構成されている
- はじめの数字は先頭のIDをあらわし、アルファベットは依存関係の種類を表す
- D 普通の依存関係
- P 調整依存
- I 不完全調整依存関係
- A 同格依存関係
- +はフレーズを表す
- 基本的なフレーズを表す
- 文節と一致するかあるいは文節の一部になる
- はじめの数字は先頭のIDを表し、アルファベットは文節と同様に定義される
- その他の行は形態素を表す
- 形態素の行は、JUMANで形態素解析を行った結果と一致する
固有表現のアノテーションは $$ タグで与えられる。$$ タグは4つの属性を持つ。
- type
- リレーションの名前
- the name of a relation
- target
- 対象となるテキスト
- the string of the counterpart
- sid
- 文のID
- the sentence ID
- id
- フレーズのID
- basic phrase ID
BCCWJ NEコーパス
BCCWJのコアデータにIREXの定義に基づきタグ付けしたコーパス
例
拡張固有表現タグ付きコーパス
現代日本語言葉均衡コーパス(BCCWJ)のコアデータおよび「CD-毎日新聞'95データ集」の新聞記事に対し関根の拡張固有表現階層-7.1.0-を人手付与したコーパス
データセットは有料で言語資源協会の方は年度中に1件目の場合に限り無料。二件目以上に当たる会員は5500円になる。非会員は33000円